Activation Functions for Deep Learning
What are Activation Functions?
At the heart of every artificial neural network there
lies a linear transformation followed by an activation function. Artificial Neural Networks (ANNs) learn to
map its input information to useful outputs information. These input output
relations are mostly nonlinear in nature which are described by complex non-linear functions. Activation
functions make ANNs capable of modeling and mimicking almost any complex
function in the world.
Major Components of an artificial neuron
An
artificial neuron has three basic components
- The synaptic links or connecting paths that provide weights wji , to the input values si for i =1,...d;
- An adder that sums the weighted input values to compute the activation value xj.
- An activation function f (also called a squashing function) that maps the activation xj to f(xj) = yj, the output value of the neuron. The individual computation element in the artificial neural network is known as the neuron unit, the network node or the processing element (PE).
Activation function f(xj) also called sometimes the transfer function has a nonlinear behavior. The value of f(xj) is denoted by yj. There are several types of nonlinear activation functions. The following is a summary of these functions

Activation value
Activation of a neuron is a linear transformations
of its inputs. The activation value is computed as
Activation
Functions (Neuron Signal Functions/Transfer Functions)
In
a neural network a neuron is the fundamental building block. When several
neuron units are grouped together and interconnected it forms neural network. Artificial
neural networks are massively parallel connectionist structures
consisting of several neurons. Neuron units in ANNs are connected in layers of
neurons. Each layer will consist of one or more neurons. Activation
functions in neural networks are used to perform nonlinear transformations of neuron
activations. Nonlinear activations gives anns the power to learn complex linear
relations between its input and its outputs. In general all units across a
given layer are the same so that the layer outputs belong to the same
probability distribution. Otherwise it will slow down the network training due
to “internal covariance shift”.
For convenience we assume that our network is simplified with one neuron unit with index "j". The unit receives its input from a "d" dimensional space. The signals from this d - dimensional vector space is indexed by "i". Inputs "sji " from this space is received via input synapses with weight values "wji" . The bias value is denoted by θj .
Threshold
logic functions
Threshold logic neuron activation function f(xj) is called a hard
limiting function. Hence the neuron takes a hard decision.
Binary Threshold (Step) Signal Function
Neurons with binary signal functions are also called binary neurons or threshold logic neuron (TLNs). Neuron output signal is based on whether xj equals/greater than zero or negative.
Binary Threshold is defined by



In engineering literature this form of a threshold function is commonly referred to as a Heavyside function.
A more appropriate representation is shown below

Bipolar (Symmetric) Threshold
The behavioural response of a two-state machine based on the threshold logic function can be extended to the bipolar case where

Signum functions
Signum functions provides a “leave-it-alone characteristic” such that when its output is zero weight updates are not performed.
Ramp
Functions
These functions are linear or linear with
threshold functions which are piece-wise linear functions.
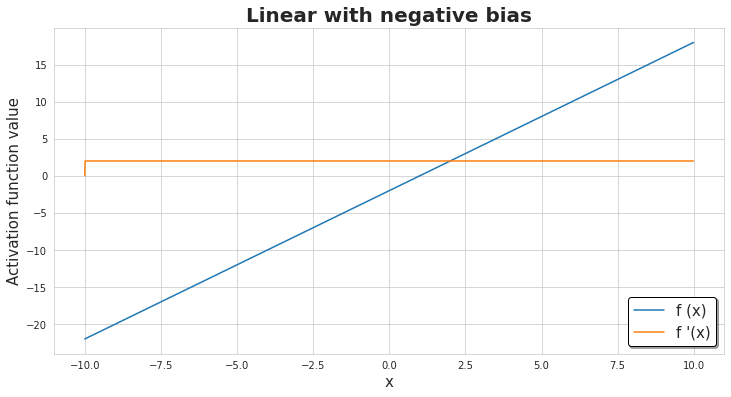
Linear Neuron: The simplest of the ramp functions is the linear function
When αj =1, the output of f(xj) is same as its input. That is f(xj) = xj (identity function). The output of linear neuron is unbounded.



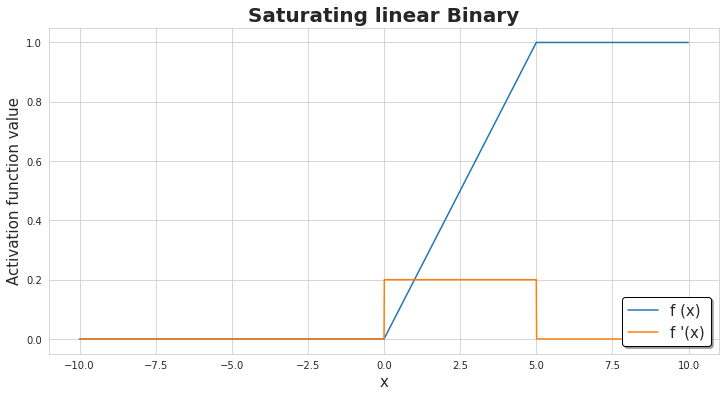
Saturating Linear Units (Linear Threshold Neuron): The bounded version of the linear signal function is saturating linear function (satlins). These are a type of piecewise linear functions. The output function of this type of neuron can be considered a combination of the linear function and threshold function.
Satlins with binary limits
This is similar to Rectified linear neuron (ReLU) functions. The output saturates to either 0 or 1.

Limitations of linear threshold functions
Linear threshold function networks are used for line fitting problems. Such functions are used to learn linear regression behavior. These functions though useful for learning linear relations between input and output for a given range of input values, lacks the ability to learn complex nonlinear input output relationships. Hence the applications of these types of activation functions are limited. A deep layer network with multiple hidden layers having only linear units can be reduced to a shallow network with only one hidden layer.
The sigmoidal (sigmoid means S – shaped) signal function is one of the most frequently used activation functions. A sigmoid function is bounded, differentiable and has a positive derivative everywhere. It is a nonlinear montonically increasing/decreasing and continuously differentiable function. These functions introduce nonlinearity model. Unlike the hard limiting activations sigmoid activation functions are soft limiting functions. Major advantage of sigmoid functions is that computation of their derivatives, essential for back propagation algorithms are easy. There are mainly two types of sigmoidal functions.
Standard sigmoid
The first one is the common logistic sigmoid function which maps its input -∞ < xj < ∞ to its corresponding output 0 < yj < 1.
where the exponential factor λj is a gain scale factor. As λj → ∞ the logistic sigmoid function approaches binary threshold function. The outputs are always positive and they tend to have a mean close to ‘0.5’.

Hyperbolic tan (tanh) function
Sigmoids which exhibit symmetry around the origin have the advantage that their outputs have an average value close to ‘0’.
The tanh function is described by the equation
Derivative of tanh
The derivative of tanh converges faster than that of standard sigmoid.

Hard Tanh
An alternative to tanh function is the Hard Tanh. It is sometimes preferred over the tanh function since it is computationally cheaper. However it saturates for magnitudes of xj greater than 1 and lesser that -1. This function is not sigmoidal.
Alternate equation of Hard Tanh
Derivative
of Hard Tanh

The soft sign function is another nonlinearity which can be considered an alternative to tanh that does not saturate as easily as hard clipped functions:
The derivative of softsign
The derivatives converge quadratically against ‘0’, which can cause problems in back propagation.

Bipolar Sigmoid
Show that this equals tanh(xj/2).

Derivative of arctan(x)

Figure-17
This
function was introduced by Yann LeCun et.al in their paper “Efficient Backprop”
in 1998.
This function is an approximation by a ratio
of polynomials and was proposed by authors since tanh is computationally
costly. The constants are chosen to keep the variance of outputs close to one,
since the gain of the sigmoid is roughly 1 over its useful range. The function
has the properties f(+/-1) = +/-1 and its effective gain over its useful range
is close to 1.

The derivatives of sigmoidal function w.r.t activation are maximum only for a small region near the center. At large magnitudes of xj the derivatives and hence the error gradients required to update the weight values tends to approximate to zero. This is called vanishing gradient problem. Vanishing gradients can cause back propagation training to come to a halt in deep neural networks and recurrent networks.
Rectified linear unit (ReLU)
A popular choice of activation function to eliminate vanishing gradients is the rectified linear unit activation function. The ReLU of enable faster training since its derivative has a constant value for half the range of values of its activation. ReLU functions are popular for image classifications. In the context of artificial neural networks, the rectifier is an activation function defined as:

ReLU was first proposed by Hahnsolver et.al in 2000 in a paper published by Nature with strong biological motivation and mathematical justifications. Since its output is zero for all negative inputs it is sparsely activated which is often desirable in networks with large number of parameters. ReLU are used only for hidden unit in deep networks.
Biological motivation and why sparsity is good?
In biological networks with billions of neurons, not all neurons fire at all times for every activity we perform. Biological neurons are task specific which are activated by different activities. In sparse networks it is more likely that a set of neurons process more meaningful aspects of the problems. Sparsity in neuron activations can improve noise robustness and also reduce overfitting problems. Another advantage is that a sparse network is faster than a dense network, since there are fewer things to compute.
Limitation the “Dyling ReLU” neuron.
A major limitation of ReLU neuron is that its output is “0” for negative value of activations. The gradient function is “0” in this activation region, neuron stops to learn how to adapt to changing input when its activation stays negative and the neuron becomes dead. This is called the dying ReLU problem. Eventually the network may end up with large number of dead neurons. This problem is more likely to occur with large learning rates and large negative bias. Other limitations are that the function is non differentiable at input equals “0” and its output blow up as xj → ∞. This is called the “exploding gradient” problem.
Variants
Leaky ReLU & Parametric ReLU (PReLU)
The major problems caused by “dying ReLU” can be mitigated by making
slight modifications. Leaky ReLU has a small slope for negative values, instead
of altogether zero. For example, leaky ReLU may have y = 0.01x when x < 0.


Leaky ReLU has two benefits:
It eliminates the “dying ReLU” problem.
It speeds up training.
Leaky ReLU isn’t
always superior to plain ReLU, and should be considered only as an alternative.
Softplus
This
function is smoother version of ReLU and solves the problem of
non-differentiability at “0”. It has the advantage that its overall saturation
is less compared ReLU.
Derivative of Softplus

Swish: A self-gated Activation Function
Prajit Ramachandran et.al of Google Brain has proposed a self-gated activation function called Swish. Self-Gating is the technique inspired by the use of sigmoid function
in LSTMs and Highway Networks. An advantage of self-gating is that it only requires a single input whereas normal gates requires multiple scalar inputs. Due to this Swish can easily replace ReLU as it also takes only a single scalar input.
Swish
is defined mathematically as:
where sig(xj) is sigmoid function.
Derivative of Swish

Smoothness of the function makes it less sensitive to initializing weights and learning rate and plays an important role in generalization and optimization. Being bounded below helps to introduce strong regularization effects.
The authors demonstrated remarkable performance increase in the networks like Inception-ResNet-v2 by 0.6% and Mobile NASNet-A by 0.9% and proved that the gradient preserving property of ReLU(having gradient equals to 1 when x > 0) is not that important.
Exponential Linear (ELU, SELU)
Similar to leaky ReLU, ELU has a small
slope for negative values and has the advantages of both ReLU and LReLU. It
uses a constant α whose value must always be positive. Similar ReLU in the
positive sided input region, but differs in the negative region by slowly
converging to –α. ELUs offer significantly
better accuracies and generalization performances than ReLUs and LReLUs on
networks with more than 5 layers. The function is
defined as
Instead
of a straight line, it uses a log curve like the following:

The function is defined as
ReLU-6
This ReLU capped at 6. In other words, it looks like the following:

GELUs full form is GAUSSIAN ERROR LINEAR UNIT
GeLU shows better accuracy than ReLU for NLP, Imaging and Speech applications. This function is used in transformers like Google’s BERT and open AI’s GPT-2. It is combination of hyperbolic tangent functions and exhibits behaviour similar to swish near small value of negative inputs.
The function is defined as
The error function erf(x) is very similar in shape to that of tanh(x)
GELU can be approximated to

The Gaussian signal function is non-monotonic signal function. It first increases smoothly from zero to its peak value of 1 at the centre and then decreases smoothly towards zero. The Gaussian function produces strong output near the centre. Far away from the centre the response becomes weak. Thus the neuron has a receptive field within which it responds to the input to generate strong output signals. Neurons with Gaussian output can be used to recognize specific ranges of inputs near a centre value using a suitable learning algorithm. Normalizing with σj√(2π) will convert this function to the Gaussian probability density distribution.

The activation (xj) of the gaussian function
can range from -∞ to +∞. The
centre cj and σj, the spread factor. For larger
value of σj the spread or
the range of inputs near the centre, to which the output is receptive,
increases. The centre can be shifted by changing the value of cj .
Logit
Consider a
classification problem with classes C1
and C2. The logistic
sigmoid activation can be used as a measure of the posterior probabilities of
the class y = P(C1|input). This means 1-y equals P(C2|input). The value of the input is a real
number in range (-∞,∞).
The logit function takes
as its input the probability measure y
and outputs a real number that range from (-∞,∞). The ratio y/(1-y) is known as the odds of the
probability . Then
its logarithm called the logit
or a.k.a log odds of y.


This activation is used
only in the output layer of ann. The base of the logarithm function used is of little importance, as long as it is
greater than 1, but the natural logarithm with base “e” is the
one most often used. The choice of base corresponds to the choice of logarithmic unit for the value: base “2” corresponds to a bit,
base “e” to a nat, and
base “10” to a ban (dit, hartley);
these units are particularly used in information-theoretic interpretations.
Softmax activation functions (Softmax/multiclass logistic regression)
For a two class problem when the logistic sigmoid function is used at the output, the network can be trained to represent the posterior probability of class conditioned on the input data. If the output value is greater than 0.5 then data classification may be considered C1 otherwise C2. Probabilistic output can be also used for multiclass classification problem. For multiclass problems considering all classes uniformly where the input data s is d-dimensional , then a softmax activation function is used which is of the form.
where Kronecker Delta
Synaptic inputs in biological neurons are essentially a noisy. Noisy processes are random in nature. This randomness can be accounted mathematically by stochastic functions or a probabilistic function.
Consider the case of a binary neuron or a bipolar neuron where the output signal is either (0,1) or (-1,1) respectively. The output of this neuron with a probabilistic function switches in accordance with the following rule.
or
The output yj of the neuron has only two states which are binary values i.e., yj ϵ {0,1} or bipolar i.e., yj ϵ {-1,1}.
References:
- Simon Haykin, Neural Networks, Pearsons education asia (2001), II edition
- Caglar Gulcehre, Marcin Moczulski, Misha Denil, Yoshua Bengio, Noisy Activations, Proceedings of the 33 rd International Conference on Machine Learning, New York, NY, USA, 2016. JMLR: W&CP volume 48.
- Yan LeCun, Leo Bottou, Genevieve B. Orr, Klaus Robert Muller, Efficient Backpropagation, http://yann.lecun.com/exdb/publis/pdf/lecun-98b.pdf
- Djork-Arné Clevert, Thomas Unterthiner, Sepp Hochreiter, Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs), ICLR 2016,, arXiv:1511.07289
- Günter Klambauer Thomas Unterthiner Andreas Mayr, Sepp Hochreiter, Self-Normalizing Neural Networks, NIPS 2017; https://arxiv.org/pdf/1706.02515.pdf
- Wenling Shang, Kihyuk Sohn, Diogo Almeida, Honglak Lee, Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units, ICML 2016, arXiv:1603.05201
- Alex Krizhevsky, Convolutional Deep Belief Networks on CIFAR-10, cs.toronto.edu. Aug 2010
- Prajit
Ramachandran∗ , Barret Zoph, Quoc V, SWISH:
A SELF-GATED ACTIVATION FUNCTION Le Google Brain, arxiv.org/pdf/1710.05941v1,
October 2017,
- Dan Hendrycks, Kevin Gimpel, Gaussian Error Linear Units (GELUs), arXiv:1606.08415v4, 2016
- https://adl1995.github.io/an-overview-of-activation-functions-used-in-neural-networks.html
- https://mlfromscratch.com/activation-functions-explained/#
- wikipedia.org



Hi
ReplyDeleteI visited your blog you have shared amazing information, i really like the information provided by you, You have done a great work. I hope you will share some more information regarding Artificial Intelligence. I appreciate your work.
Thanks
Have a Great Day
Using machines, we can also expect the same kind of results irrespective of timings, season and etc., those we can’t expect from human beings.
ReplyDeleteVicky from Way2Smile Solutions DMCC - Top Digital Transformation Company in Dubai.
Great post, thanks!
ReplyDeleteML
best machine learning course online
ReplyDeleteMachine Learning Online Training In Hyderabad